Imagine you're a security researcher, and you scan the internet and find an exposed /debug/pprof on somecompany.com. You are happy, submit your bug hoping for an easy high severity issue that leaks memory and all sorts of goodies. (lets pretend that's true, and /debug/pprof leaks more than function names, and leaks useful information about the actual state of the program as opposed to some pretty graphs).
Why can't the developer just remove the /debug/pprof route. I want my payout and I can't believe they say it'll take weeks to resolve!
Follow me on a hypothetical journey trying to resolve this issue at a company larger than 1 team.
the life of a simple http request
To the happy user this is all they see, and its very straight forward. I hit the website and I collect my $2000 when I pass go.
But in reality. it might be something like this 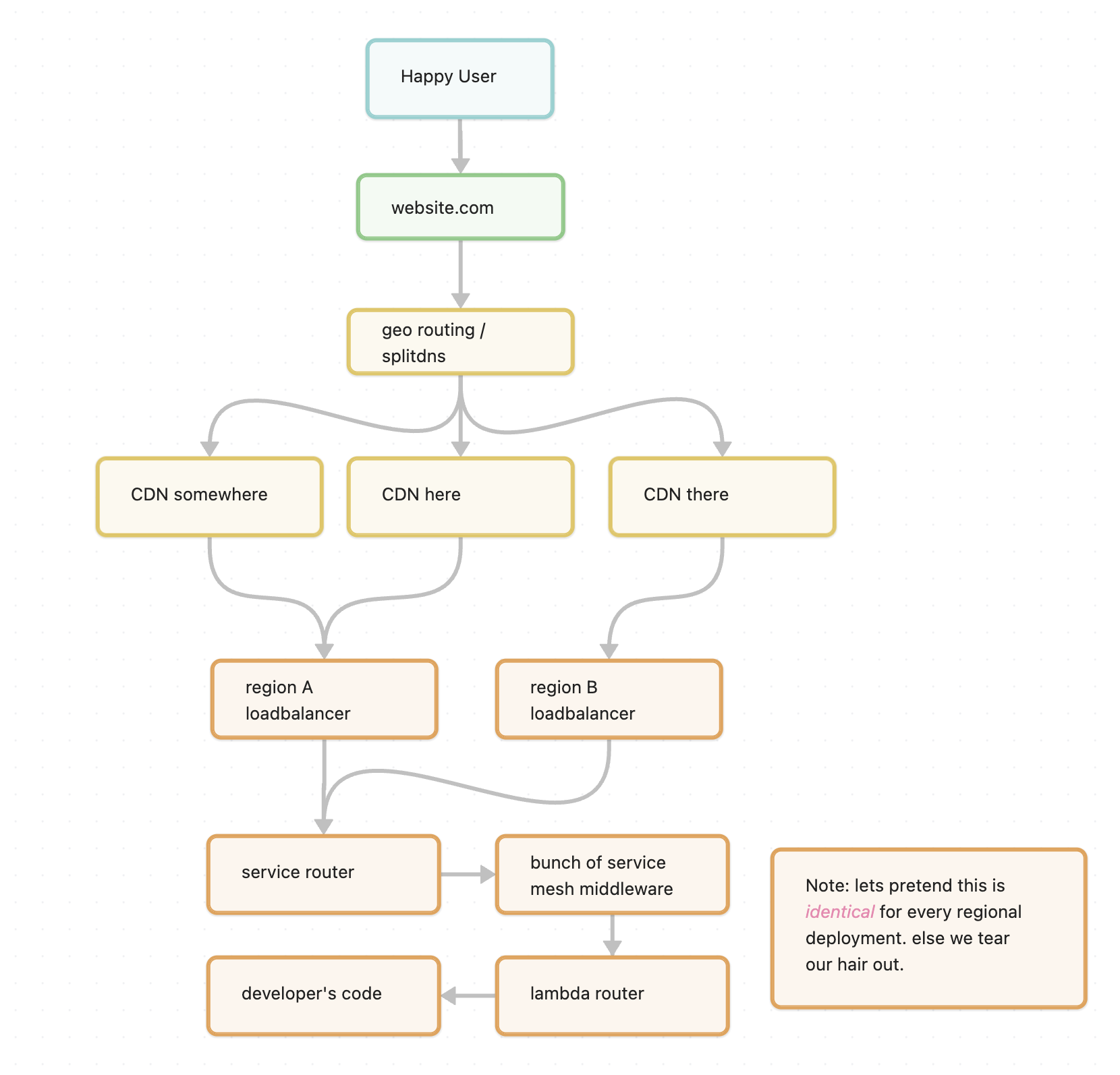
So to a very confused security engineer we now have to figure out who do we talk to fix this problem.
It could be caused by the developer's code. Or:
- by our lambda router service
- by the service mesh middleware that processes the request
- our routing service
- the L7 load balancers maintained and built in-house
- a CDN provider if they're doing crazy L7 processing as well
The user's reverse proxy if they're doing really wild things and don't realise they've pointed example.com to 127.0.0.1
Well lets first figure out what code and what domain is being routed here. Given we have a split-view domain, it could be routing to any one of our many data centers around the world. The reporter hasn't told us where they live, so lets pray that its identical everywhere.
Luckily for us we can relatively easily look up the domain and it routes to our lambda platform. There's an ID for the corresponding lambda. A few permission requests and 24h later we can finally see the lambda. But hold up, the lambda is written in Python. Why are we getting a golang /debug/pprof?
Lets check our distributed tracing logs. Its a production service, so debug and trace logging is gone, and our service router reports its being received and forwarded to the lambda service. Aaand that's it. No other traces. Well at least we know its after the service router. 
Well ok, well maybe I could try and bisect the problem by isolating each component. Wait, I neither own the service nor have permissions to modify anything in this path because its a production application serving millions of users. and potentially 10s of thousands of QPS.
How about I message some SREs in the path and hope they direct me somewhere useful? Nope, everyone points me to someone else because it doesn't seem to be their service that causes the problem. Excellent.
We're now 3 days after the initial report, and we know its not the developer's code, and its after the service router somewhere. Do we try and dig into the mesh middleware? or try something else.
Ok, lets provision our own lambda and MCVE it. Reading through a dozen docs, half of which tell us what we're doing is deprecated and we should move to Lambda Service 2.0. We start setting things up, send out another half dozen approval requests to ship a new production domain, service name, and lambda. Another day or two gone trying to replicate this one bug that is apparently very critical.
Coming back to the office on Monday, we start piece by piece stepping through whats happening, fiddling with all sorts of switches enabling / disabling middleware, routers and configurations. Huzzah, turns out using this particular configuration between the service router, lambda router and developer's code results in the lambda router exposing its /debug/pprof endpoint. Turns out the deprecation notice had some reason after all. Also the impact isn't as great as we hoped, since the lambda router is sharded such that we get only the traffic for this deployment.
Wait but then how do we fix it. Do we ask a developer to redeploy their service to a non-deprecated platform? Its the end of Q2, and everyone is rushing to ship out their features so they can claim they had a killer Q2 performance. No way in hell we'll convince anyone to spend a few days re-plumbing a service that doesn't contribute to their north star this quarter.
Is there an easy configuration switch to disable it? Nope, its baked into the lambda router and we're not going to convince them to turn off their profiling that's used internally.
I've lost track of when the ticket came in, it might have been this month, or last month. 
So how do we fix this ticket and get our friend his glorious payout?
Fuck it. Akamai WAF - Add a rule for /debug/pprof, block mode on. Onto the next ticket.
epilogue
In reality, this Q2 bug becomes a Q3 fix, with two more sync meetings with a PM and an engineer explaining why they need to build in more sane defaults that won't expose publicly the endpoint for free. This comes with a free task to audit of all your internal configurations and catch any other variants of the same issue across your entire infrastructure. As a bonus, you get to spend another week figuring out how to regression test this so all future deployments don't have it again, and no one accidentally reintroduces the bug.If you're lucky, you'll have someone report that 1 edge case you forgot to consider, and then bundle in a free consultation about how an ASM like product can solve this problem for you.